Chapter 5: Amazon Simple Storage Service (S3)
Introduction to storage options on AWS
Different use cases require different storage architecture for performance, reliability, durability.
3 primary storage options:
- Block storage
- File storage
- Object storage
Block storage
Block storage = an storage architecture design that enable store data onto media (e.g. hard disk) in fixed size chunks (i.e. each block has same size)
- Working principle: data is broken into small blocks and placed on the media, each block has a corresponding unique address assigned. These addresses are saved in metadata
- Data Retrieval: management software identify the blocks to retrieve, reassemble data into file to be represented.
- AWS service to offer block storage:
- Elastic Block Store (EBS), can be configured as volumne attached to EC2
- Characterstic of block storage: ultra-low latency required for high-performance workload
- EBS are not directly attached to EC2, but mounted as storage as EBS volume via high-speed network links
- Use cases:
- system files used by ES2 OS
- used as DAS (direct-attached storage) or storage area network (SANs)
File storage
File storage = architecture offers a centralized location for corporate data
- Offer hierarchical structure to store data (i.e. in folders and sub-folders)
- Data Retrieval: need to know file location and folder structure
- Use cases:
- corporate file sharing
- AWS service:
- Elastic File System (EFS) = managed elastic filesystem designed to share file data without provisioning or managing storage.
- Filesystem can grow or shrink based on need
- Support mount EFS on Linux EC2 instances (not Windows)
- FSx for Lustre = High-performance filesystem desgined for GB throughput and millions of IOPS (input/output operations per seconds)
- Support Linux-based EC2 instances
- FSx for Windows File Server = designed for Microsoft Windows EC2 instances.
- Elastic File System (EFS) = managed elastic filesystem designed to share file data without provisioning or managing storage.
- Con: folder structure sometime reduce performance of R/W
Object storage
Object storage = storing complete files as individual objects.
- Unstructured data: Object storage is a flat file structure. Objects are stored without folder or file-level hierarchy.
- Object storage metadata (e.g. name, etc) and other attributes are used to create unique identifier to locate the object
- Benefit of using object storage:
- metadata: rich information within metadata enable easy data analytics than other storage architectures
- high performance, durability and scalability. As it does not have file structure.
- AWS service:
- S3: AWS let you create container called bucket, to store objects
- Use cases:
- Store digital assets for web/app (e.g. document, images, video)
Introduction to Amazon S3
Amazon S3 offer up to 99.99999999999% durability (eleven 9s)
Buckets and objects
- Step before upload data to Amazon S3: create a bucket (i.e. container)
- A bucket need a unique global namespace
- unique across AWS ecosystem
- Hard to find common names. Usually combined with corpo name
- unique across AWS ecosystem
- Bucket content can be directly accessed over public internet (after configuration) via two ways:
- Virtual hosted-styled endpoints:
- S3 Uniform Resource Locator (URL) consists of 2 parts
- part 1: Domain Name System (DNS) subdomain name, which contains bucket name
- part 2: object name
- e.g.
https://just-desserts.s3.amazonaws.com/blueberry-muffin.txtwherejust-desserts.s3.amazonaws.comis DNS subdomain name - It need DNS config
- S3 Uniform Resource Locator (URL) consists of 2 parts
- Website endpoint: bucket is configured with a static web hosting service, and available at AWS Region-specific endpoint:
- format 1: s3-website dash (-) Region
http://<bucket-name>.s3-website-Region.amazonaws.com
- format 2: s3-website dot (.) Region
http://<bucket-name>.s3-website.Region.amazonaws.com
- format 1: s3-website dash (-) Region
- Virtual hosted-styled endpoints:
- You cannot have nested bucket (i.e. no bucket within bucket)
- Each bucket has one URI
Object storage:
- An object is stored in entirety, instead of broken into chunks like block storage
- Maximum size of one object (5 TB)
Key & Value:
- Key of object = filename of the object
- Value = data contained in object
Managing your objects in a bucket
S3 bucket is flat filesystem. But object name can mimick file structure using prefix & delimiter (/). It still has ONE SINGLE object name.
e.g. Amazon S3 prefix and delimiter
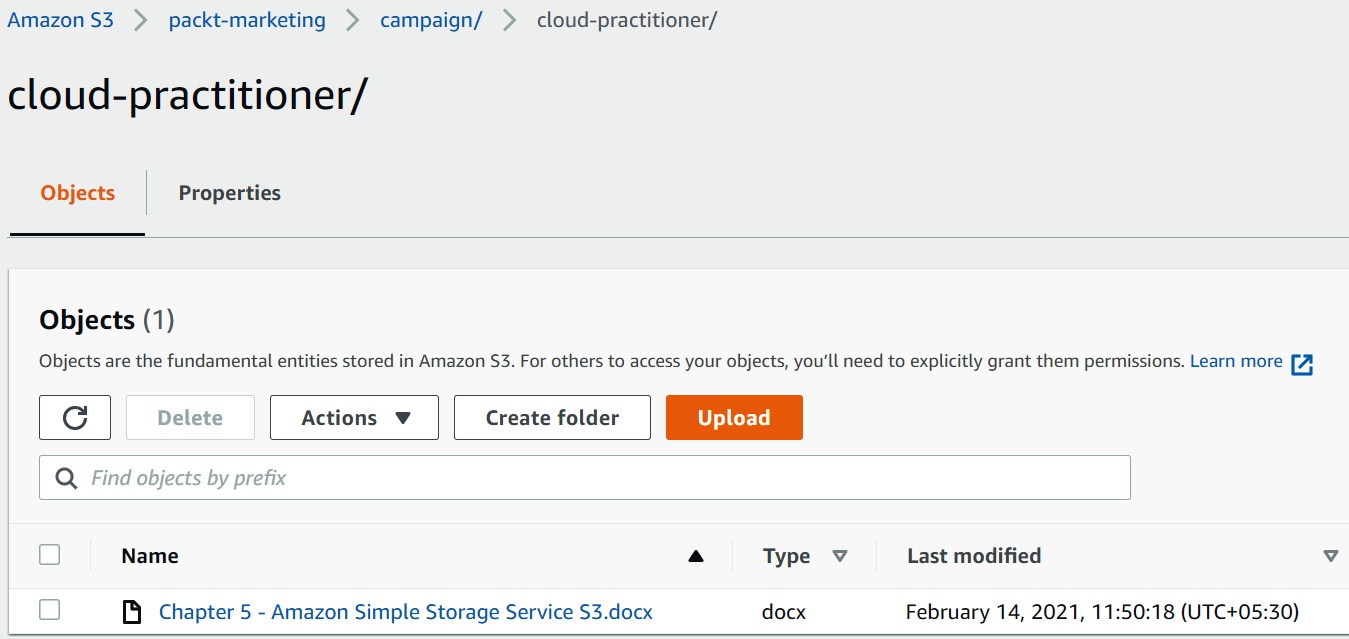
Where:
- packt-marketing is bucket name
- campain & cloud-practitioner are sub-folder name
Benefit of prefix:
- Help to limit search results
- Enhance access performance
Regional hosting - global availability
- After configuration, buckets & objects are globally accessible.
- But S3 buckets are stored in Regions, which impact latency and cost for accessing resources
- AWS does not replicate data outside the chosen Region
Access permissions
S3 has 2 primary methods of granting access to resources:
- bucket policy
- access-control lists (ACLs): legacy
Bucket policies
- Bucket policy is applied to entire bucket and objects within it
- policy document written in JSON
- Bucket policies grant cross-account access (i.e. user or app in other AWS account) by specifying AWS ID or IAM user Amazon Resource Name (ARN) from the other AWS account
How to define policy: similar to IAM policy, you need define attributes within Statement
"Action": action to be taken on the bucket (e.g.s3:GetObject)"Effect": Allow or Deny"Resource": Bucket ARN, wildcard(*)can apply"Principle": if given*, it means available for anyone"Condition": conditional policy to be added on bucket, to create filter
e.g. of typical bucket policy granting anonymous access to contained objects
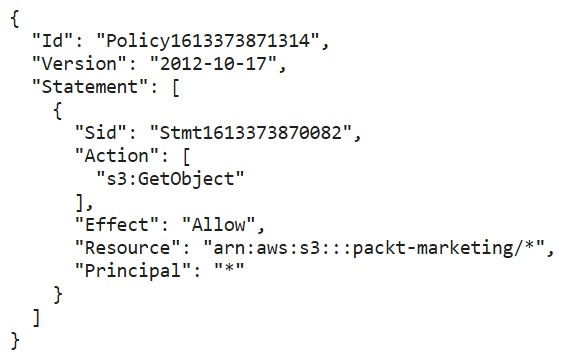
e.g. bucket policy of conditional statement

IAM policies
Other than bucket policies and ACLs (outdated), you can create IAM policies to be assigned to IAM identities (e.g. IAM users, groups, or roles).
Problem of IAM policies:
- IAM policies cannot be attached directly to resources.
- IAM policies cannot be attached to IAM user from ANOTHER AWS account.
- IAM policies cannot be used to grant anonymous access
Solution:
- Create an IAM role with necessary permissions
- Enable trust policy for other AWS account's IAM users to assume this role
Choosing the right S3 storage class
S3 charges are based on 6 cost components:
- Storage (amount of storage, duration, storage class)
- Requests and data retrievals
- Data transfer
- User of transfer acceleration
- Data management
- Analytics
- (optional) Use of S3 Objct Lambda: used to modify and process data during data extraction using Lambda function
A single bucket can contain any type of data. No need to create separate buckets for each storage class
Different storage classes:
- Frequent access
- S3 Standard: default storage class, detailed attributes are in table below
- Infrequent access
- S3 Standard-Infrequent Access (S3 Standard-IA)
- S3 One Zone-Infrequent Access (S3 One Zone-IA)
- Archive storage
- Amazon Glacier
- Amazon Glacier Deep Archive
- Unpredictable access patterns
- Intelligent-Tiering: another storage class offered by AWS. Object are automatically transitioned across 4 different tiers
- S3 on Outposts
Figure below show S3 storage performance
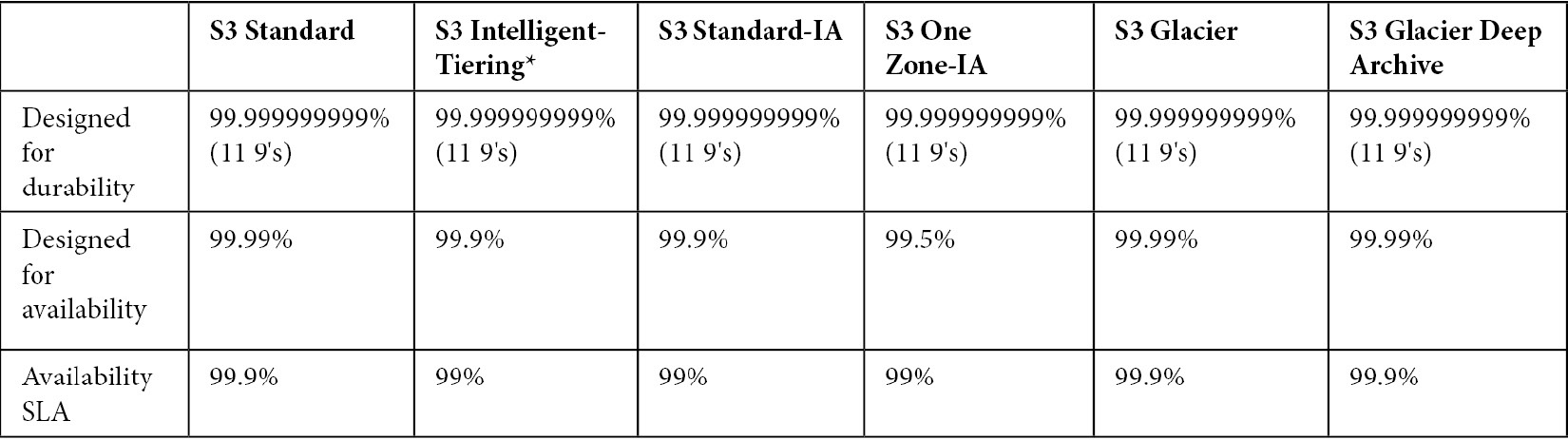
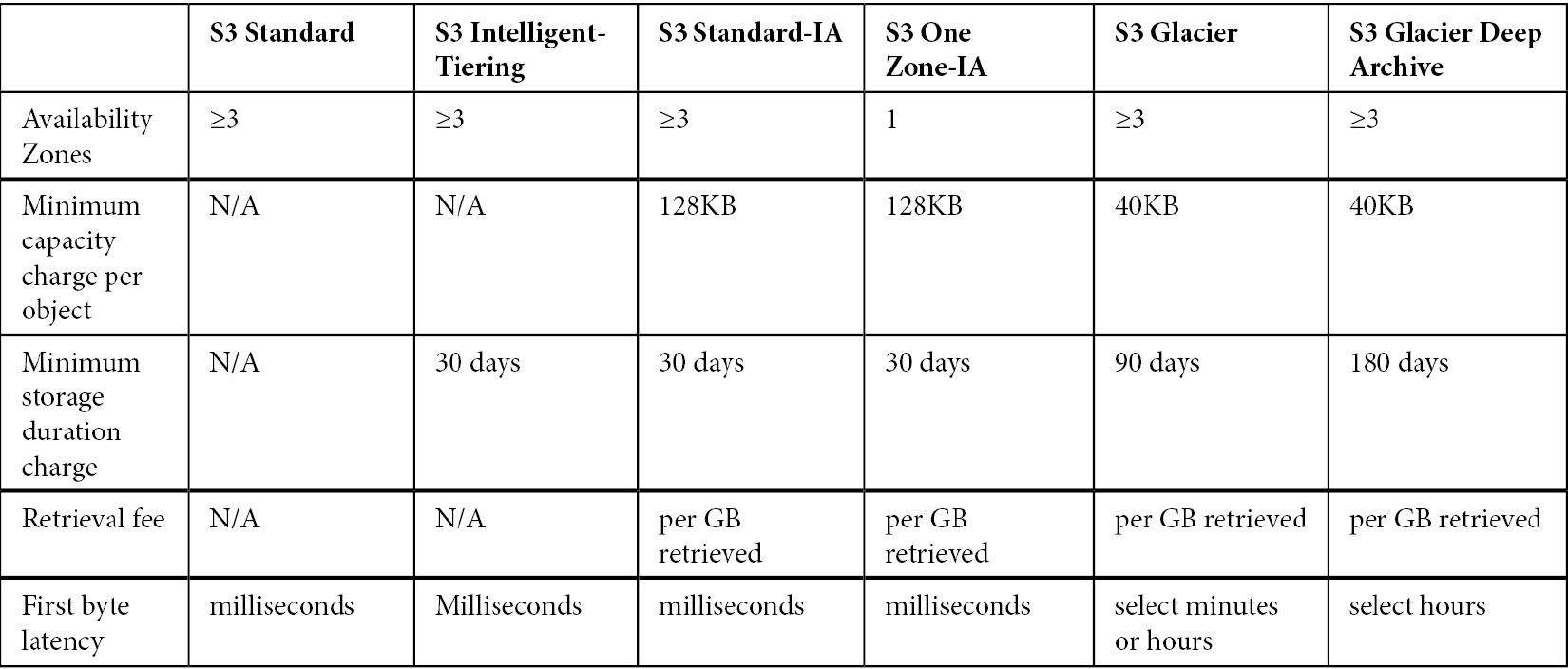
Figure below show S3 storage class key attributes
Versions
S3 Versioning
- Feature offered by S3 service
- Disabled as default when the bucket is created
- Once enabled
- uploaded will be tagged with a new version ID, if there is existing object key (i.e. name)
- Delete an object simply add a delete marker to the object, and hide from S3 console. Hence, object can be recovered by delete the delete marker
3 state of bucket in terms of versioning:
- Unversioned (default)
- Versioning-enabled
- Versioning-suspended
Once enable versioning, you cannot return to Unversioned state, but you can suspend versioning
Cross-Region and same-Region replication
By default, AWS never copy your data out of your Region, but AWS offer provide service to do so:
- Amazon Cross-Region Replication (CRR):
- copy object acorss AWS buckets in different Regions async
- Use cases:
- Reduce latency
- Increase operation efficiency: app in different Region need access to same dataset
- Meet regulatory and compliance requirement
- Same-Region Replication (SRR):
- provide replication service btw buckets in same Regions
- Use cases:
- Log Data Aggregation: log data can be saved in a single management bucket via replication
- Replicating between development and production accounts: Move objects from development AWS account to production AWS account.
- Compliance requirements: required to maintain multiple copies of data to adhere to data-residency laws.
Note: versioning must be enabled to set up CRR or SRR
S3 Life cycle Management:
- solution provided to manage vast quantities of data, when there is need to manage life-cycle of objects (upload -> maintain -> destroy)
- S3 Life cycle Management actions can be attached to buckets or subset of data
- 2 category of actions:
- Transition actions: move objects from one storage class (e.g. S3 -> Glacier) to another after a certain period of time
- Expiration actions: delete objects from S3 storage system after a set number of days. (e.g. delete after 1 year)
S3 encryption
- All data uploaded to Amazon S3 is encrypted in transit using HTTPS protocol. But after transition, stored data are unecrypted by default.
- Encryption at rest: encrypt data before storing in S3.
AWS offers 3 options for encrypting data at rest
- Server-side encryption: When you upload (create) an object, S3 encrypts it before saving it to disk. When you download it, it's decrypted by S3 service. S3 have 3 options
- Server-side encryption with Amazon S3-managed keys (SSE-S3) - Amazon encrypts your data with a 256-bit Advanced Encryption Standard (AES-256)
- Server-side encryption with customer master key (CMKs) stored in AWS Key Management Service (SSE-KMS)
- Server-side encryption with customer provided key (CPKs) (SSE-C) stored in AWS
- Client-side encryption
Static website hosting
Amazon S3TA
- Problem to solve: host S3 bucket in a specific Region, but require users across the globe to upload objects to it.
- Solution: S3TA routes your uploads via Amazon CloudFront's globally distributed edge locations and AWS backbone networks.